
RandomForestClassifierのパラメータ
RandomForestClassiferには主に以下のようなパラメータがあります。他にもありますが今回は省略します。
| n_estimators | 決定木の個数(≠深さ) |
| criterion | 分割基準(giniまたはentropy) |
| max_features | ノード分割する際に考慮する特徴量数。整数で指定した場合はその個数、小数の場合は全特徴量 数 に対する割合、autoは全特徴量 数 のルート数、log2はlog2(全特徴量数)。 |
| max_depth | 決定木の深さ。過学習を避けるのが目的。 |
| random_state | 乱数生成を制御するパラメータ。これを指定することで毎回発生する乱数を固定化する。 |
| n_jobs | 使用するCPUのコア数。-1にすると全CPUコアを仕様。デフォルトは1となり並列実行はしない。 |
| min_samples_split | 末端ノード内の最小サンプル数。整数で指定した場合は個数、小数の場合は全体に対する割合。 |
| verbose | 実行時のログ出力。verbose=1:経過時間と実行数を表示。verbose=2:各ツリーの構築に関する残りの情報を表示。 |
パラメータの最適解を強引に探すのがGridSearchCV
しかしながら、パラメータをチューニングといってもどこからどう手を付けて行ったら良いのか?がわかりませんし、毎回あれこれ試行錯誤するのも時間がかかります。
そこで、「わからないなら片っ端から調べて最適解を見つけよう!」というやり方がGridSearchCVです。
GridSearchCVの使い方
GridSearchCVの使い方の手順は以下のとおりです。
- RandomForestClassifierのパラメータを用意
- 予測モデルやパラメータを用いてGridSearchCVオブジェクトを作成
- GridSearchCVに学習用データを当てはめる
- 最適パラメータ、最適モデルを取得
- 予測
パラメータを用意
まず最初にRandomForestClassifierで試したいパラメータを用意します。今回は、とりあえず以下の6つを設定してみます。
| n_estimators | 1000 |
| criterion | ‘gini’,’entropy’ |
| max_features | 0.1,0.25,0.5,0.75,1.0 |
| random_state | 1 |
| min_samples_split | 3, 5, 10, 15, 20, 25, 30, 50, 100 |
| max_depth | 3, 5, 10, 15, 20, 25, 30, 50, 100 |
n_estimators、random_stateについては固定としていますが、決まった値だけを使用したい場合は、このように1つだけ値を用意すればOKです。
補足
n_estimatorsを1つだけにしている理由については、「なぜn_estimatorsやepochsをパラメータサーチしてはいけないのか」が参考になりました。
random_stateも乱数の発生を決めるものなので、1つだけで構いません。
予測モデルやパラメータを用いてGridSearchCVオブジェクトを作成
次に、GridSearchCVオブジェクトを作成します。
from sklearn.model_selection import GridSearchCV
GridSearchCV(estimator, param_grid, scoring=None, n_jobs, cv=None, verbose=0, refit=True)GridSearchCVの主な引数は、以下の7つです。
| estimator | チューニングを行うモデル(今回はRandomForestClassifier()) |
| param_grid | 上記のモデルでチューニングを試したいパラメータ({パラメータ名:[値のリスト]}の辞書として入れる |
| scoring | 評価関数( ‘accuracy’, ‘precision’, ‘recall’ などを配列として入れる) |
| n_jobs | 同時使用CPU数(-1なら全CPUを使用) |
| cv | Cross validationの分割数(defaultは3分割) |
| verbose | ログの表示方法 |
| refit | Trueの場合、最適解で全学習データを使って再学習を実施 |
GridSearchCVに学習用データを当てはめる
GridSearchCVオブジェクトを作成したら次に学習用データを当てはめます。これはこれまで行った予測モデルと同じようにfit(説明変数,目的変数)とするだけです。
from sklearn.model_selection import GridSearchCV
gs = GridSearchCV(RandomForestClassifier(), search_params, cv=5, verbose=2, n_jobs=-1)この時、オブジェクト作成時に設定したverboseの値によって、出力されるログが異なります。下記はVerbose=1と設定したときのログです。最初の「Fitting 5 folds for each of 810 candidates」はクロスバリデーションで5分割して、検証するパラメータの組み合わせが全部で1×2×5×1×9×9=810種類ある事を意味しています。

最適パラメータ、最適モデルを取得
終了したら最適パラメータと最適モデルを取得します。
best_param = model_tuning.best_params_
best_estimator = model_tuning.best_estimator_最適モデルを表示すると下記のようになります。

予測
最適モデルはそのまま使えるので、テストデータを当てはめて予測します。結果は前回と同様にCSVファイルに出力します。
y_pred = best_clf.predict(test_dataset)
PassengerId = np.array(test_csv['PassengerId'].values)
my_result = pd.DataFrame(y_pred, PassengerId, columns=['Survived'])
my_result.to_csv('titanic_gridseachcv_randomforestclassifier2.csv', index_label='PassengerId', encoding='utf-8')まとめ
今回のGridSearchCVを使ったTitanic課題用のPythonプログラムは下記のようになります。
from sklearn.model_selection import GridSearchCV
# RandomForestClassifierで使用するパラメータ
search_params = {
'n_estimators' : [1000],
'criterion':['gini','entropy'],
'max_features' :[0.1,0.25,0.5,0.75,1.0],
'random_state' : [1],
'min_samples_split' : [3, 5, 10, 15, 20, 25, 30, 50, 100],
'max_depth' : [3, 5, 10, 15, 20, 25, 30, 50, 100],
}
# GridSearchCVのオブジェクトを作成
gs = GridSearchCV(RandomForestClassifier(), search_params, cv=5, verbose=2, n_jobs=-1)
# 学習用データを適用
gs.fit(X_train,y_train)
# 最適モデルを取得
best_clf = gs.best_estimator_
# テストデータで予測
y_pred = best_clf.predict(test_dataset)
# Kaggleにアップロード用のCSVファイルの作成
PassengerId = np.array(test_csv['PassengerId'].values)
my_result = pd.DataFrame(y_pred, PassengerId, columns=['Survived'])
my_result.to_csv('titanic_gridseachcv_randomforestclassifier2.csv', index_label='PassengerId', encoding='utf-8')このCSVファイルをKaggleにアップロードすると、

わずかですが新記録達成です。
GridSearchCVは時間がかかるので工夫が必要
GridSearchCVはモデルの学習を繰り返すのでその分時間がかかります。今回私の場合は、約35分で終わりましたが、その間CPUやメモリはほぼMaxでしたので、他の作業は全くできませんでした。
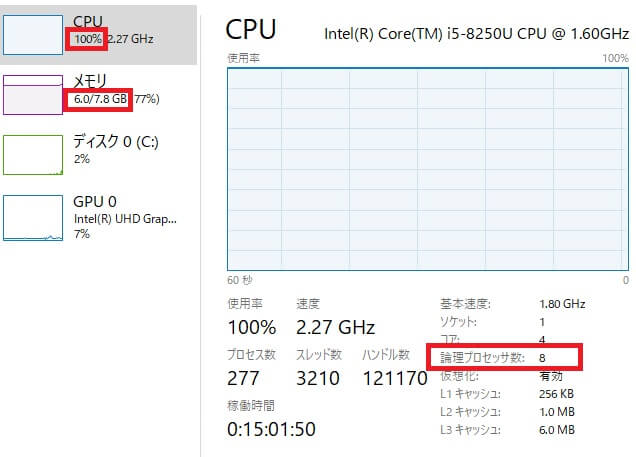
実を言うと、これでも各パラメータの配列の数を減らしました。今回はパラメータの組み合わせは810パターンでしたが、最初試したときは1200パターン以上あり、2時間以上かかりました。
GridSearchCVは最適解を見つけるのですが、その分時間がかかり運が悪いとフリーズすることもあります。そのため、GridSearchCVを行う前にパラメータの範囲に目星をつけておくことがとても重要です。
次回は、パラメータの範囲の見つけ方を紹介したいと思います。
]]>

コメント