
今度はランダムフォレスト(RandomForestClassifier)を使ってみます。
手順
今回の手順は以下のとおりです。基本的には前回と変わりません。
- ファイルの読み込み
- 前処理
- 予測モデルの作成
- テストデータで予測
- 検証
ファイルの読み込み
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
train_csv = pd.read_csv('train.csv')
test_csv = pd.read_csv('test.csv')前処理
次に前処理ですが、下記の3つを今回は関数を作って1つにまとめます。
- 不要なカラムの除去
- 欠損値を埋める
- カテゴリ変数の変換
def replace(df, args):
ret = df.copy()
ret = ret[args] # 指定したカラムのみ抽出
ret['Age'] = ret['Age'].fillna(df['Age'].median()) # Ageの欠損値を平均値で埋める
ret['Embarked'] = ret['Embarked'].fillna(ret['Embarked'].mode().iloc[0]) # Embarkedの欠損値を最頻値で埋める
ret['Fare'] = ret['Fare'].fillna(df['Fare'].median()) # Fareの欠損値を平均値で埋める
ret = pd.get_dummies(ret)
return retこのreplace関数では、データと抽出するカラム名の配列を引数に指定することで前処理を行います。
まずは学習用データ(train.csv)で前処理を行います。学習用データではSurvived,Pclass,Age,Sex,Fare, SibSp, Parch, Embarkedの8カラムを使います。
train_arg = ['Survived','Pclass','Age','Sex','Fare', 'SibSp', 'Parch', 'Embarked']
train_dataset = replace(train_csv, train_arg)
print(train_dataset.shape)
print(train_dataset.isnull().sum())
train_dataset.head(10)
必要なカラムだけ抽出して、欠損値もなく、カテゴリ変数(Sex、Embarked)が変換されていることが確認できました。
同様にテスト用データ(test)も行います。テスト用データはSurvivedがないのでそれ以外のカラムを抽出します。
test_arg = ['Pclass','Age','Sex','Fare', 'SibSp', 'Parch', 'Embarked']
test_dataset = replace(test_csv, test_arg)
print(test_dataset.shape)
print(test_dataset.isnull().sum())
test_dataset.head(10)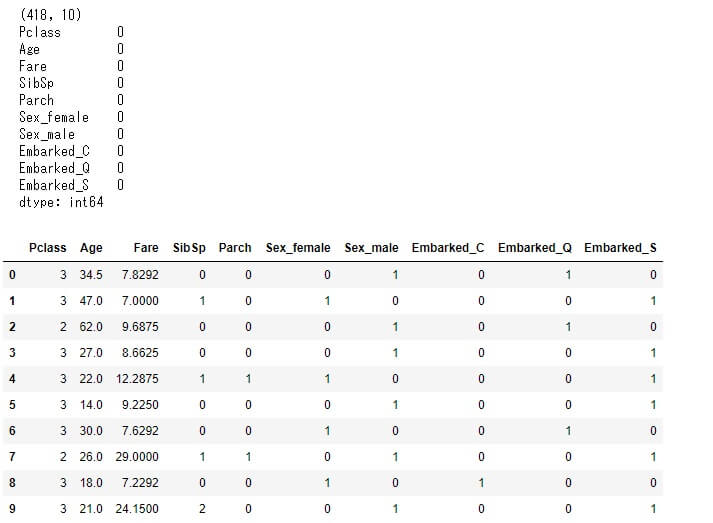
こちらもきちんと変換されていることが確認できました。いよいよ予測モデルの作成に入ります。
予測モデルの作成
学習用データから目的変数と説明変数を取得し、ランダムフォレストクラスを作成してから目的変数と説明変数を入れて実行すると下記のようなメッセージがでます。
x_train = train_dataset.iloc[:,1:].values
y_train = train_dataset['Survived'].values
rfc = RandomForestClassifier(verbose=1, n_jobs=-1, random_state=0)
rfc.fit(x_train, y_train)
今回は特にパラメータの設定をしておりませんが、今回入れたパラメータは
| verbose | モデル構築の過程のメッセージを表示。デフォルトは0(=非表示) |
| n_jobs | 複数のCPUコアを使って並列に学習を実施。デフォルトは0。-1はすべて使う。 |
| random_state | 乱数値の組を指定 |
そしてテストデータで予測します。
y_pred = rfc.predict(test_dataset)結果をCSVファイルに出力して、Kaggleへアップロードします。手順については前回の記事と同じになるので省略します。
PassengerId = np.array(test_csv['PassengerId'].values)
my_result = pd.DataFrame(y_pred, PassengerId, columns=['Survived'])
my_result.head()
my_result.to_csv('titanic_randomforestclassifier.csv', index_label='PassengerId', encoding='utf-8')Kaggleで検証した結果、

なんと、まさかの前回より悪い結果に。。。
これでは諦めきれませんので、次回はパラメータチューニングを行います。
]]>

コメント